主题
模型详情页
模型详情页提供了单个 AI 模型的完整信息,包括模型能力、定价详情、性能指标和 API 调用示例,帮助你全面了解模型特性并快速集成到你的应用中。
访问详情页
在 AI 模型市场 中点击任意模型卡片,即可进入该模型的详情页。
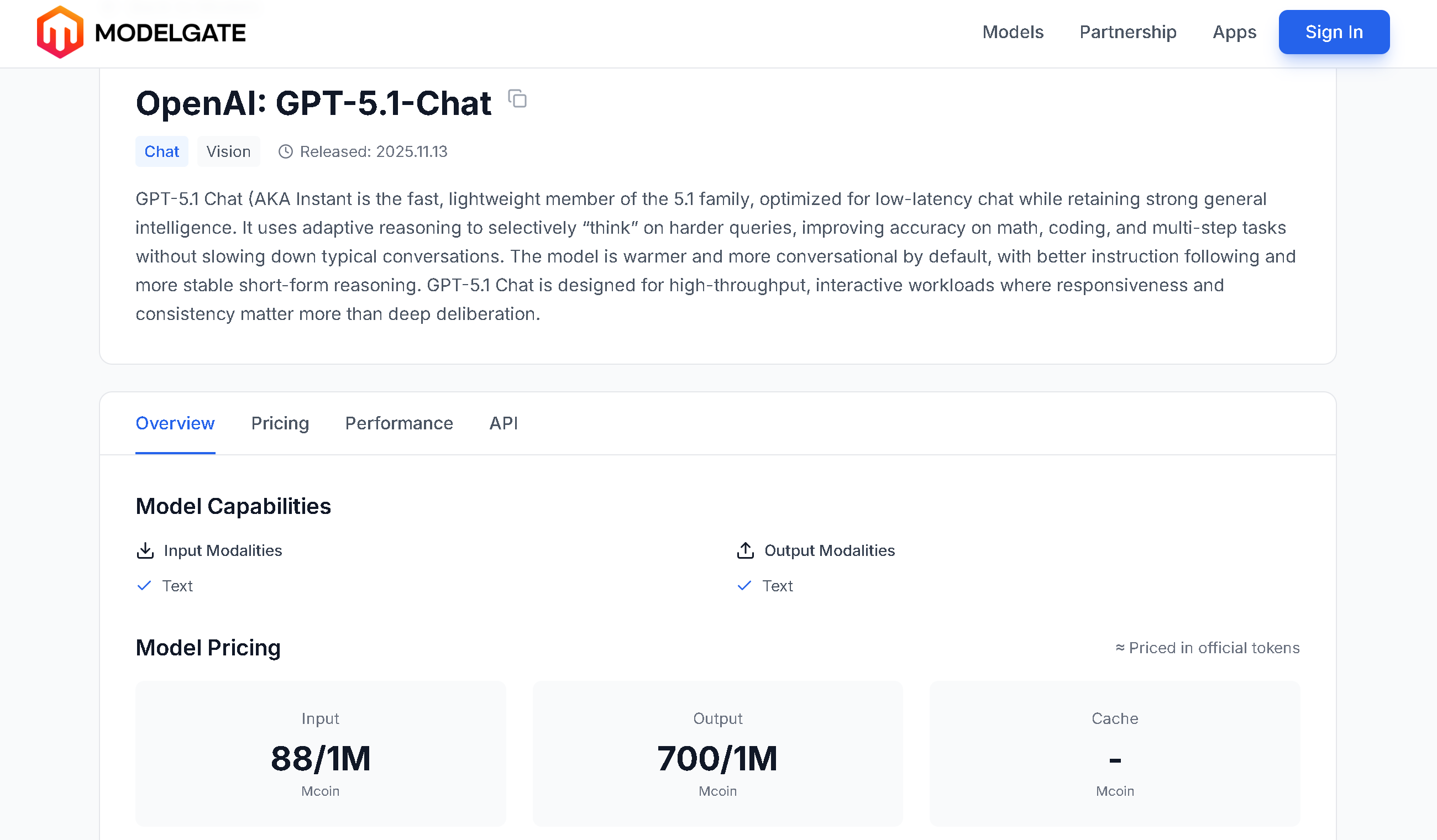
模型基本信息
页面顶部展示模型的核心信息:
- 模型名称: 完整的模型名称,点击右侧的复制按钮可快速复制模型名称
- 提供商: 模型的服务提供商
- 类型标签: 模型类型(Chat、Reasoning、Image、Video)
- 功能标签: 模型支持的能力(如 Vision、Function Call、Tools、Coding 等)
- 发布日期: 模型的发布时间
- 模型描述: 详细介绍模型的特点、能力和适用场景

Overview(概览)
展示模型的核心能力和基本配置信息。
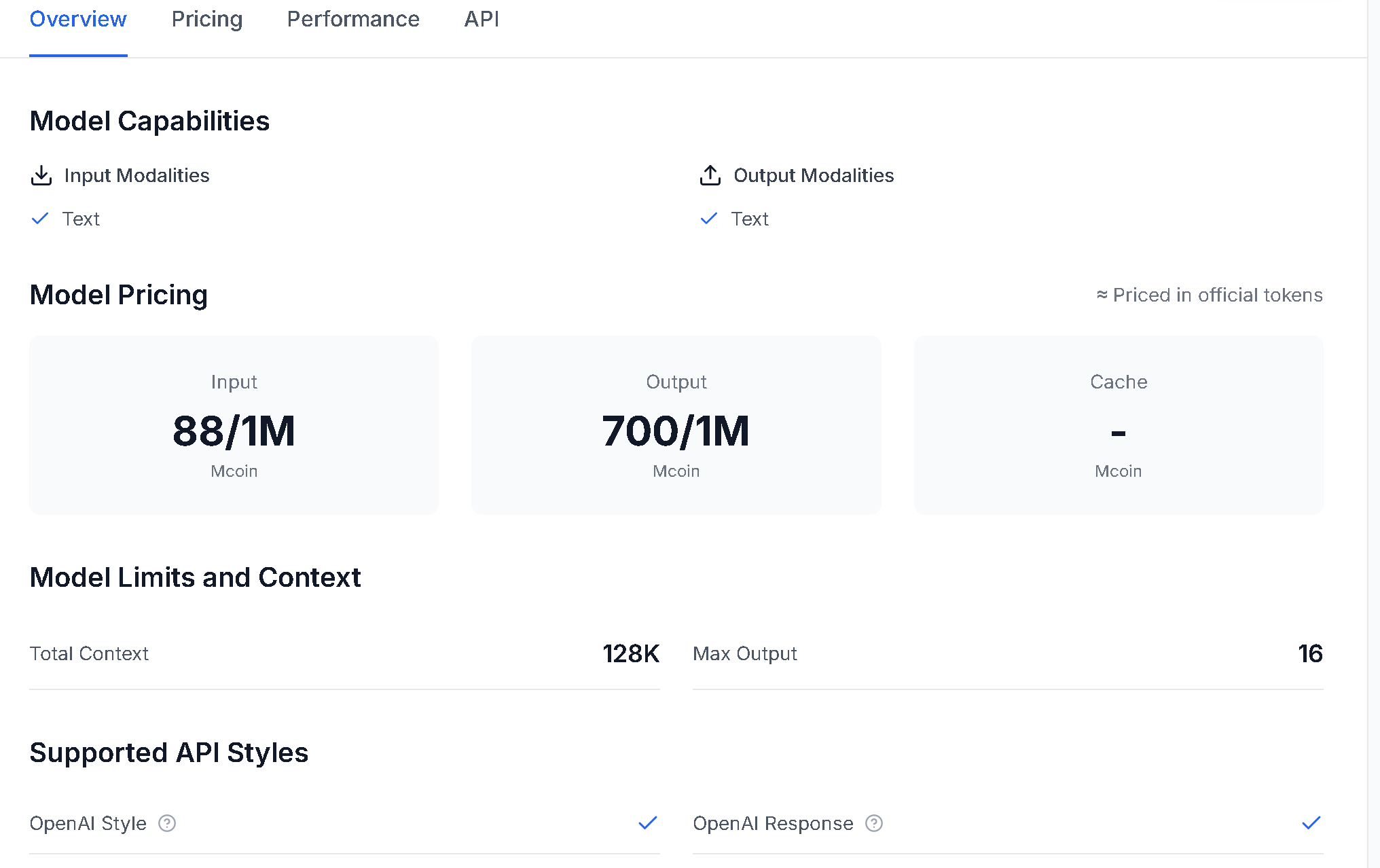
模型能力(Model Capabilities)
输入模态(Input Modalities)
模型支持的输入类型:
| 输入类型 | 说明 |
|---|---|
| Text | 支持文本输入 |
| Image | 支持图像输入(视觉理解能力) |
输出模态(Output Modalities)
模型支持的输出类型:
| 输出类型 | 说明 |
|---|---|
| Text | 支持文本输出 |
模型定价(Model Pricing)
展示模型的基础定价信息:
- Input: 输入价格(Mcoin/M tokens)
- Output: 输出价格(Mcoin/M tokens)
- Cache: 缓存价格(Mcoin/M tokens),部分模型支持缓存功能以降低成本
说明: 价格以官方 token 计算单位为准
模型限制和上下文(Model Limits and Context)
展示模型的技术限制:
- Total Context: 总上下文长度,如 128K 表示支持 128,000 个 tokens 的上下文
- Max Output: 最大输出长度,单次请求最多可生成的 token 数量
支持的 API 风格(Supported API Styles)
| API 风格 | 说明 | 适用场景 |
|---|---|---|
| OpenAI Style | 最常用的兼容风格,可访问几乎所有大模型 | 适用于所有模型,兼容性最好 |
| Anthropic Style | Claude 官方风格,满足 Claude 模型完整数据支持 | 仅 Anthropic 提供的模型显示 |
| Google Style | Google Gemini 官方风格,支持所有 Gemini 特性 | 仅 Google 提供的模型显示 |
| OpenAI Response | OpenAI 原生响应格式,提供完整的响应数据 | 仅 OpenAI 提供的模型显示 |
鼠标悬停在问号图标上可以查看每种 API 风格的详细说明。
Pricing(定价)
展示不同提供商分组的详细定价信息。
分组说明
ModelGate 将请求路由到能够处理你的提示大小和参数的最佳提供商,并提供故障转移机制以最大化正常运行时间。
每个分组包含以下信息:
分组标识:
- 分组名称(如 Premium、Balanced、Budget)
- 折扣标签:显示相对基础价格的折扣比例
性能指标:
- Latency: 平均延迟时间(秒)
- Throughput: 吞吐量(token/s)
- Availability: 可用性百分比
定价信息:
| 项目 | 单位 | 说明 |
|---|---|---|
| Input | mcoin/M | 输入价格,按百万 tokens 计费 |
| Output | mcoin/M | 输出价格,按百万 tokens 计费 |
| Cache | mcoin/M | 缓存价格,使用缓存功能的费用 |
说明:
- Premium (品质)分组通常提供最佳性能,但价格较高
- Balanced (均衡)分组平衡了性能和价格
- Budget (特价)分组提供最优惠的价格,适合预算有限的场景

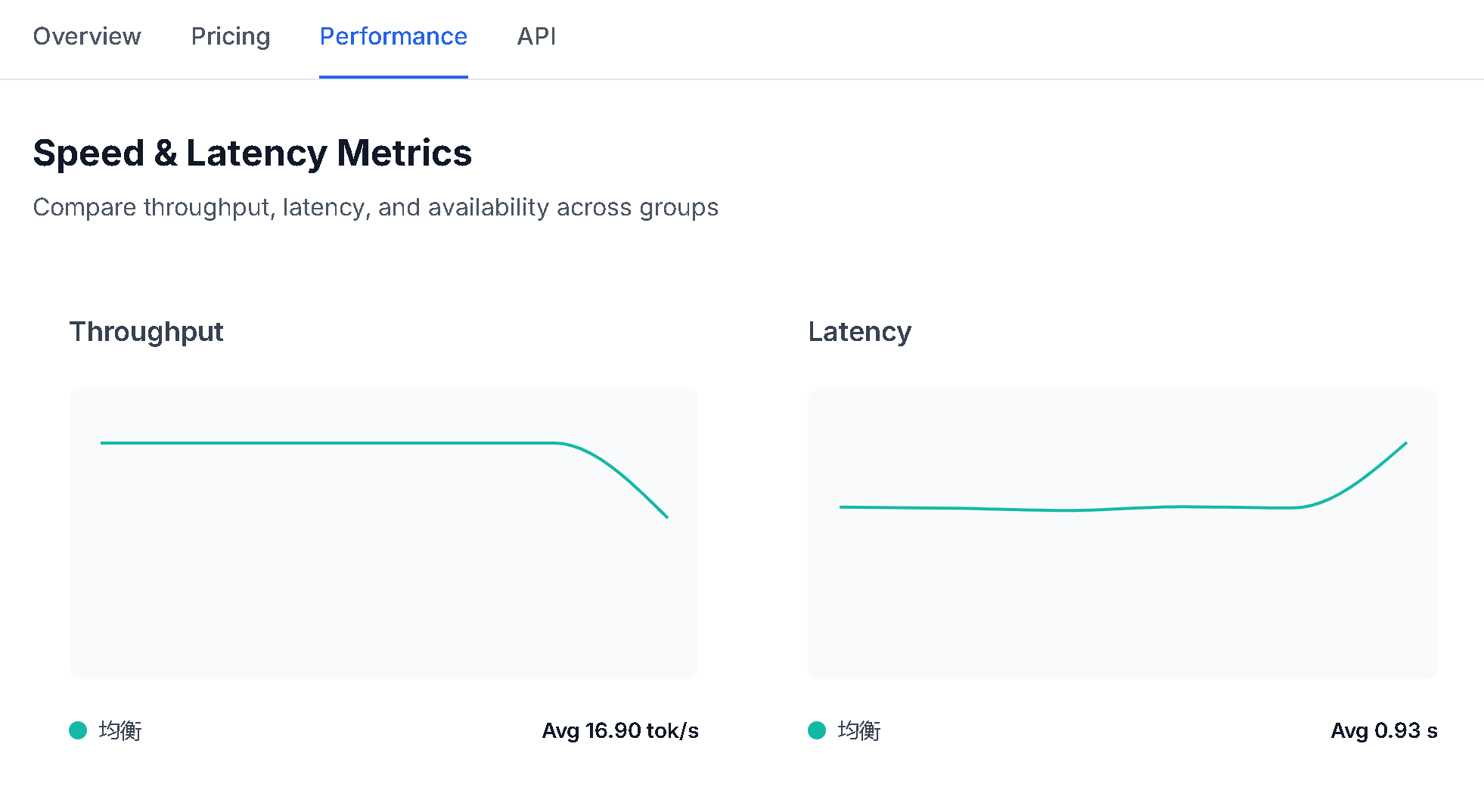
Performance(性能)
展示模型在不同提供商分组下的实时性能数据。
吞吐量(Throughput)
展示各分组的输出吞吐量趋势图:
- 单位: token/s(每秒生成的 token 数)
- 说明: 吞吐量越高,模型生成内容的速度越快
- 平均值: 图表下方显示每个分组的平均吞吐量
延迟(Latency)
展示各分组的延迟趋势图:
- 单位: 秒(s)
- 说明: 延迟越低,模型响应速度越快
- 平均值: 图表下方显示每个分组的平均延迟
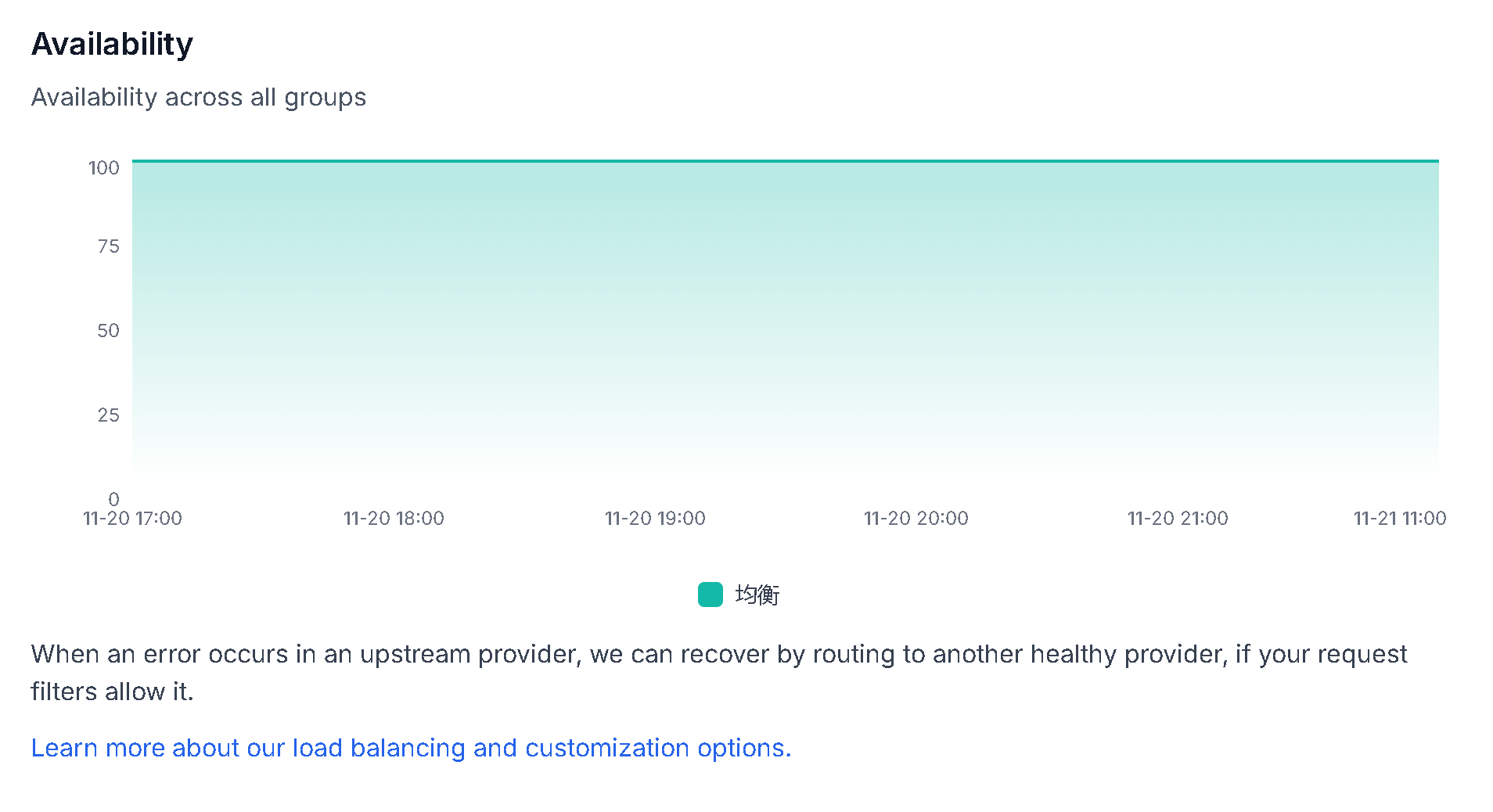
可用性(Availability)
展示各分组的可用性趋势:
- 单位: 百分比(%)
- 说明: 可用性越高,服务越稳定可靠
- 时间范围: 图表展示最近一段时间的可用性变化
容错机制:
当上游提供商发生错误时,ModelGate 可以自动路由到另一个健康的提供商,前提是你的请求过滤器允许这样做。
性能数据说明
- 图表展示的是实时监控数据
- 鼠标悬停在图表上可以查看具体时间点的数值
- 不同颜色的线条代表不同的提供商分组
- 可以通过性能数据选择最适合你需求的分组
常见问题
如何复制模型名称?
点击页面顶部模型名称右侧的复制按钮,即可将模型名称复制到剪贴板。在 API 调用时需要使用这个准确的模型名称。
不同的 API 风格有什么区别?
- OpenAI Style: 兼容性最好,适用于所有模型,但部分特定参数可能不支持
- Anthropic Style: 专为 Claude 模型优化,支持 Claude 特有的功能
- Google Style: 专为 Gemini 模型优化,支持 Gemini 特有的功能
- OpenAI Response: 提供完整的响应数据,包括详细的 token 使用统计
建议:优先使用模型提供商对应的原生 API 风格,以获得最完整的功能支持。
如何选择合适的策略?
在 Settings → API Keys 中创建或编辑 API Key 时,可以设置 Model Preference(模型偏好策略)。当使用同名模型时,系统会根据所选策略自动选择最合适的提供商:
| 需求场景 | 推荐策略 | 说明 |
|---|---|---|
| 生产环境,稳定性优先 | Availability First | 优先选择可用性最高的模型,确保稳定的服务体验 |
| 成本敏感,预算有限 | Price First | 优先选择价格最便宜的模型,降低使用成本(可能影响可用性和速度) |
| 实时应用,响应速度优先 | Speed First | 优先选择延迟最低、输出速度最快的模型,提供最佳性能体验 |
提示: 不同的策略会影响系统如何在 Premium、Balanced、Budget 等提供商分组中进行选择。
性能数据多久更新一次?
性能数据是实时监控的,图表展示的是最近一段时间的实际数据。每次访问 Performance 标签都会从服务器获取最新数据。
为什么有些功能没有显示?
- 部分 API 风格仅在特定提供商的模型上显示
- 某些功能(如 Cache)可能只有部分模型支持
- 如果模型较新,部分历史性能数据可能尚未完整
如何获取 API Key?
请参阅 快速开始 文档,了解如何创建和管理 API Key。